

When building your voice agent, you’ll have to decide which voice architecture you’ll use. There are three architectures you can choose from, each with their own pros and cons. In this blog post, we’ll define each one and compare them, so you can decide which one better suits your needs.
The 3 voice architectures
Let’s start by defining the different architectures.
- Cascade pipeline: it consists of 3 main components – a speech-to-text (STT) model that transcribes audio into text, so that the large language model (LLM) can process it and generate a text response, which is streamed to the text-to-speech (TTS) model to be converted into audio.

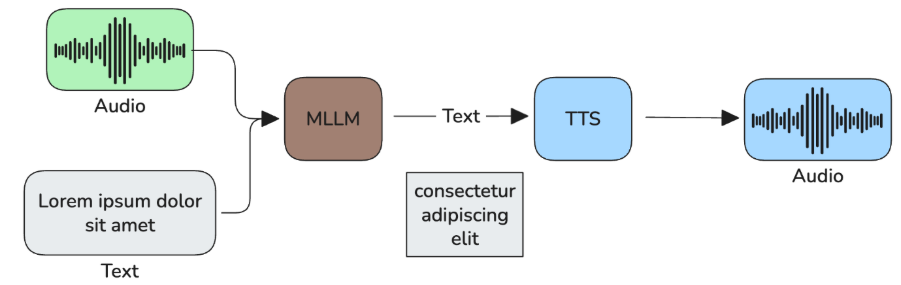
- Half-cascade pipeline: it consists of two components – a multimodal large language model (MLLM) that can consume audio directly and returns a textual response that is passed on to a TTS model.
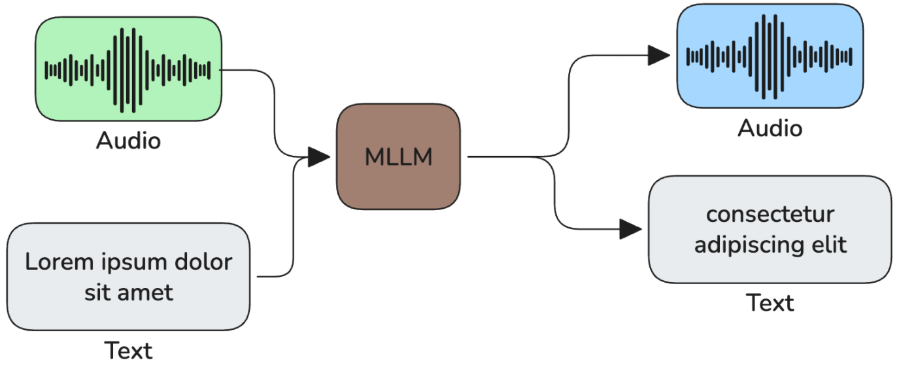
- Speech-to-speech models: a MLLM that can both consume and output audio.
Voice activity detection and turn detectors
There are two more components that add up to this pipeline to enable a smooth voice conversation and that are often not mentioned when talking about voice architectures. Those are the voice activity detection (VAD) and the turn detection models.
These models are a relevant part of the pipeline that allow the agent to know when the user has ended their “turn”. For realtime APIs, such as OpenAI realtime or Google Live API, which serve speech-to-speech models, this is already integrated, so you can use server side turn-detection. If you prefer, though, you can disable it and use your own.
The turn detector model works in conjunction with VAD and this tends to perform best then to just use VAD alone. This is because VAD only detects when there's speech or not. This doesn't mean the user ended their turn. They may speak slowly or do brief pauses to think. Turn detector models, however, use context cues to better determine when the user ended their turn. So, when VAD detects there's no speech, the turn detector model is triggered to determine if the absence of speech is an end of turn, or not.
Both VAD and turn detector models tend to be small models that can run locally on a CPU. An example of a VAD model is silero VAD, and examples of turn detection models are Livekit’s MultilingualModel and Pipecat’s smart turn.
Comparison
Definitions alone only take you so far. That’s why we’ve made a comparison between the different architectures, ranging from the available providers, to the naturalness and performance of each architecture.
Available models/APIs
Regarding available models and APIs, the cascade architecture has several providers, both open-source/weight and managed solutions. Examples include ElevenLabs, DeepGram, or Cartesia for the STT; GPT, Gemini, or Deepseek for the LLM; and ElevenLabs, Inworld, or Hume for the TTS.
As for the half-cascade and speech-to-speech architectures, there aren’t that many providers at the time of writing. A notable example of a provider for the half-cascade architecture is Ultravox, which has its own managed solution as well as its open-weight models.
Other examples include OpenAI’s realtime API, which supports both the half-cascade and speech-to-speech architecture, or some AWS Sonic models. Google’s Live API only supports speech-to-speech architectures.
Voice Cloning
Voice cloning is often a requirement for voice AI apps as companies want to have a personalized voice that is unique to their brand. On this matter, the cascade and half-cascade pipeline, since they rely on an external TTS provider, allow for this feature. Providers such as ElevenLabs or Cartesia support voice cloning. These services tend to offer instant voice clones, where you just need to provide a few seconds of the voice you want to clone, but also professional voice clones, where the minimum is around 30min of recordings. Professional voice clones tend to be more accurate and represent the voice more faithfully than instant voice clones.
As for speech-to-speech providers, this doesn’t seem to be as standard as it is for TTS models. OpenAI seems to support voice cloning, but only for eligible customers, whereas Google doesn’t seem to support this for their Live API at the moment.
Custom voices
Custom voices differ from voice cloning in the sense that you can create a custom voice without cloning one. For example, TTS providers like Eleven Labs have this feature where you can create a brand new voice via prompting. Just describe the voice you want (e.g., “middle-aged man with a strong Scottish accent.”) and a voice will be generated in seconds.
That being said, and since the cascade and half-cascade architectures rely on a separate TTS provider, they both have support for custom voices. For speech-to-speech models, similar to voice cloning, this doesn’t seem to be a widespread feature you can use.
Failure points
Regarding the points of failure, cascade architectures have 3: the STT, the LLM, and the TTS. If one of these components fails, it will jeopardize your system, so it’s good to have fallbacks. For example, your main STT provider might be DeepGram, but if their service is down you might fallback to Cartesia. The same goes for the LLM and TTS components.
As for the half-cascade architecture, it has one less point of failure since there’s no STT component and the speech-to-speech architecture has just a single failure point.
Latency
In what concerns latency, the cascade architecture is, generally, the slowest of the three. You have to concatenate three models/APIs together, so if you use a managed service/API, this will amount to 3 network roundtrips. Nevertheless, nowadays, the time it takes to generate a response is quite low, allowing for realtime conversations.
Following this logic, the half-cascade architecture will be faster than the cascade one, and the speech-to-speech architecture is the fastest of the three.
Naturalness
With the cascade architecture, the system may struggle to interpret sarcasm or certain intonations that change the meaning of a sentence, as the model generating the response only has access to the transcript (what was said) and not the audio (how it was said).
The half-cascade architecture is, in theory, more natural than the cascade architecture (as the model consumes the audio directly, so it can interpret paralinguistic cues), but not so natural as speech-to-speech models, which are the most natural of the three (besides receiving the audio directly, they can also change the acoustics of the audio response).
Performance
In what concerns performance, cascade architectures, as they rely on text language models, are, currently, the best at instruction following and tool calling. Speech-to-speech models are still falling short of cascade pipelines. However, Ultravox, which follows the half-cascade architecture tends to be better at instruction following and tool calling than speech-to-speech models, although not as good as a textual LM – see Benchmarking LLMs for Voice Agent Use Cases.
Summary table
| Features/Architectures | Cascade | Half-cascade | Speech-to-speech |
|---|---|---|---|
| Available Models/APIs | Several • STT: ElevenLabs, DeepGram, Cartesia, etc. • LLM: GPT, Gemini, Deepseek, etc. • TTS: ElevenLabs, Inworld, Hume, etc. … |
Not many • OpenAI Realtime API • Ultravox (not available in European environments) • AWS Sonic … |
Not many • OpenAI Realtime API • Google Live API • AWS Sonic … |
| Voice Cloning | Yes. The TTS component is independent and providers such as ElevenLabs support it. | Yes. The TTS component is independent and providers such as ElevenLabs support it. | OpenAI appears to allow voice cloning at the moment of writing. |
| Custom Voice | Yes. The TTS component is independent and providers such as ElevenLabs support it. | Yes. The TTS component is independent and providers such as ElevenLabs support it. | Possible via cloning on OpenAI, but it is not possible to create a synthetic voice the way you would with a standalone TTS. |
| Failure Points | 3 – STT, LLM, and TTS. | 2 – MLLM and TTS. | 1 – MLLM. |
| Latency | Depends on the model combination, but will typically be higher than the other two architectures. | Depends on the model combination, but will typically be higher than the speech-to-speech architecture. | Fastest of the 3 – fewer network roundtrips and processing is handled by a single model. |
| Naturalness | May struggle to interpret sarcasm or certain intonations that change the meaning of a sentence, as the model generating the response only has access to the transcript. | More natural than the cascade architecture (as it can consume the audio directly and interpret some paralinguistic cues), but less natural than speech-to-speech. | Most natural. |
| Performance | The best at instruction following and tool calling. | Ultravox specifically tends to be better at instruction following and tool calling than speech-to-speech models, but it is not as good as a textual LM | Still not as good as the other two architectures in terms of instruction following and tool calling. |
What architecture should you use?
All in all, cascade pipelines still tend to be the most used for complex production use cases, where your agent has to strictly follow a set of instructions and call multiple tools. They may be slower and less natural, but if accurate responses are a must, they are still the best option. However, if your use case is simpler and naturalness is a must, you may want to try a speech-to-speech model via OpenAI’s realtime API or Google’s Live API. Bear in mind that options are limited at the time of writing when compared to the cascade pipelines. Nonetheless, the trend seems to be moving towards speech-to-speech models.
To backup this claim, just a few months ago (October 2025), Google stated that “It [half-cascade architecture] offers better performance and reliability in production environments, especially with tool use.”. Now, though, Google no longer supports the half-cascade architecture, only native audio (speech-to-speech) models, which seems to hint they are moving towards speech-to-speech. Moreover, Ultravox AI’s CEO Zach Koch has written the Why Speech-to-Speech is the Future of Voice AI blog post, where he argues that “the era of component stacks is ending” (aka, cascade pipeline) and that “the future speaks speech-to-speech”.
In what concerns the half-cascade architecture, Ultravox is a solid solution, but as shown above, it might migrate to a speech-to-speech architecture in the future. As for OpenAI’s realtime API, or even Amazon Sonic, it’s not clear whether they will follow the same path as Google and remove the support for the half-cascade architecture.
Conclusion
The cascade architecture is still the prevailing one for voice AI solutions, but “speech-to-speech models are closing the gap”. However, since stitching together a voice AI app is becoming increasingly simple, make sure you test at least two of the architectures to get a sense of how well they work for your use case. Frameworks like livekit or pipecat, for example, make it easy for you to create your voice app.