

The path to Machine Learning and AI is not a simple or easy one. On the philosophical side, the field is young and our society is still grappling with what these technologies mean for our humanity. On the practical side, there is no clear one-size-fits-all recipe for an organization that wants to start implementing AI systems. Much to the disappointment of ye old innovation department and impatient executive, we are here to advocate for an approach that is a delicate (and somewhat boring) balancing act between quick wins and infrastructure. Let’s inspect both sides of this AI strategy in detail starting with Quick Wins.

Quick Wins
Few organizations have the resources to dump the millions (or dare I say billions) into true AI moonshots that can take years to produce monetary results. This is essentially VC work and is only possible with piles of cash and an institutional willingness to wait years for an ROI that may never come. Asking organizations to make bets on anything that takes more than some months to see measurable results is not only bound to fail on a project level but actually endangers the future of the organization by disincentivizing them to pursue said path. For better or for worse, most of our economic systems are quarterly based and thus don’t allow long-running initiatives much leeway. This is especially true for the organizations that we aim to help in pursuit of our Vision.
For better or for worse, most of our economic systems are quarterly based and thus don’t allow long-running initiatives much leeway
On a more practical side, Quick Wins can actually help you prepare to play the long game. ML and AI are essentially data driven automations (see this episode of Explained for an excellent non-technical explanation) and anyone who has automated a process knows that you have to understand it first. Furthermore, aiming for Quick Wins will force you to research and build out some very minimal infrastructure which can provide valuable context that is required for longer-term investments. Lastly, and most importantly, Quick Wins provide internal and external stakeholders (especially executives) with the proof they need to justify further investment.
Some real life examples of quick wins that have eventually led to longer-term strategic and infrastructure work:
- 1 week: Data analysis to understand the impact of a price increase on sales.
- 1 week: Analysis of client usage of a web app’s free trial period to understand how much time it takes until the client as effectively converted.
- 2 weeks: Benchmark of a Machine Learning for churn prediction using Microsoft Azure cloud tools.
- 4 weeks: Benchmark of a Machine Learning sales forecasting system to see if a pre-selected minimum accuracy could quickly be achieved.
- 6 weeks: Report generation of clients that are at risk of churn — included charts describing recent client behavior to support decision making.
Give that this blog post has the words “path to AI” , how does it make any sense to include things that are seemingly very basic and generic analysis tasks? It’s simple: working with data is the foundation of Machine Learning and AI. Understanding of your data is essential to be able to train statistical models and analysis is all about understanding your data. It also gives you a chance to use modern tooling which in itself is very informative. If your organization is not able to support a basic analysis task with modern tooling, then it is clear that you have a long way to go. Conversely, if it goes well, the time spent can both generate value as well as illuminate the path forward which gives you your next steps.
working with data is the foundation of Machine Learning and AI
Quick Wins are absolutely essential. Don’t invest millions in long term strategy development. Invest tens of thousands in Quick Wins and watch the long term plays grow from there.
Infrastructure
Making the shift from focusing on Quick Wins to the more strategic focus on Infrastructure doesn’t, on the surface, look that different. You should still maintain an outcome-oriented focus. You should still quickly and continuously deliver value. Key stakeholders shouldn’t be waiting more than weeks for new value to be delivered in key projects. The reason that we start by focusing on Quick Wins has to do with human nature itself and this does not change.
When focusing on infrastructure, the biggest shift is HOW the work is done. Rather than running to the finish line as fast as possible without planning on re-using anything that is built, you widen the size of the effort in order to ensure things are engineered correctly. To understand what I mean, let’s walk a conceptual path using the following stepping stones:
- Understand what a “Narrow Effort” is
- Understand what a “Wide Effort” is
- Understand when and how the “widening” of an effort pays off
Narrow Efforts
A Narrow Effort is, on its own, not a bad thing. Narrow Efforts allow for laser-sharp focus on achieving the desired outcome of a single project or initiative with speed as the primary objective. At the very beginning of any project, you should be making a Narrow Effort because you just don’t know if it’s going to pay off or not. You need to reach the desired outcome as quickly as possible just to discover if it can be done! Any extra effort other than what is absolutely required is likely to risk more time, energy, and resources than necessary.
You need to reach the desired outcome as quickly as possible just to discover if it can be done!
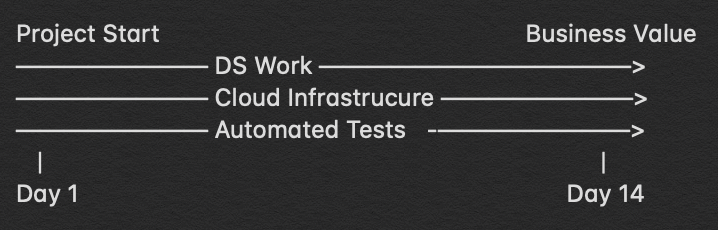
Let’s take one of the quick wins that we described in the previous section and take a closer look at it to understand why it is a Narrow Effort. We will use the first one which is “Data analysis to understand the impact of a price increase on Sales”.
- Step 1: Get the data. We email someone asking for a couple of excel spreadsheets for the last 2 years of sales data. They respond in an email with said excel sheet and we put it into a shared file system and it becomes the source of truth for this dataset.
- Step 2: Explore the data. We create a single code repository and start DS Work. We put everything into a few different folders in an attempt to organize things but don’t think too hard about naming conventions, code organization, testing, reviews because all of these take time.
- Step 3: Draw Conclusions. The person leading the project will arrive at a few conclusions. In this case, she conclude that the price increase did not seem to have a significant effect on Sales. She will ask a colleague to review it quickly just to make sure there are no obvious mistakes.
- Step 4: Communicate the results. The Data Scientist that drew the conclusions takes screenshots of the key charts and pastes them into a quickly prepared presentation that can be given to the client. The client understands the results and gives the go-ahead to raise the price of the product across all their stores. We plan to do another analysis in the future to ensure that the conclusions continue to hold.
Note that in this case “DS Work” (Data Science Work) is exploring the data but in general this can also include training ML models, designing dashboards, building ETLs, building data pipelines, etc.
The desired outcome was quickly achieved. However, the technical work and processes were very sloppy and have (at the very least) the following problems:
- The excel sheet was from a person and not the true source of the data which is a database somewhere. It could have been corrupted by human error and you have no way to get an updated version of the data in case you want to repeat the analysis again in the future without involving (potentially expensive) man hours.
- The single code repository which was not tested, organized, and thoroughly reviewed has a much higher chance for errors. Furthermore, if someone else wants to jump in and take the project over in the future, good luck reading and understanding the code that someone wrote as fast as they could over the course of a few days.
- Screenshots into presentations is a very manual process that has lots of places for human error. Plus, the only person that can run the code is a Data Scientist which puts a significant barrier to accessing the knowledge.
Let’s take a moment to visualize a Narrow Effort:

In this Narrow Effort, there is one thread of focus and it is very narrow — the only thing that matters is the x-axis which is time. We are reducing the total number of things that could go wrong and only really trying to do one single thing as fast as possible. Now what happens if we need to do another version of the project in which we need an updated version of the data, make changes to the code, and generate a different type of business value. You’ll get to save some time by reusing some of the code but the project time will still be similar:

Even worse, imagine another scenario in which the original dev is not around and you need to make even the smallest change. The new dev is going to have to read and understand all of the code from top to bottom. They will have to find all hidden assumptions and infer every critical decision because of the lack of documentation. This can result in even the smallest change to what was originally a 2 week project looking something like this:

Anybody who has run a dev team knows what this looks like. And most current data science teams are run like this because they are being run by Data Scientists who have limited experience in the insanely difficult field that is Software Engineering.
As mentioned, a Narrow Effort is not inherently a bad thing. A Narrow Effort does, however, becomes dangerous when confused with a sustainable solution.
Wide Efforts
So imagine that you need a solution to last longer than the few weeks it takes to gain a Quick Win using a Narrow Effort. How can you do this without incurring crippling technical debt? The answer is to widen your effort. As we saw with our Narrow Efforts, there is one single thread of laser-focused drive to meet a very small set of business requirements. So let’s take our previous visualization which only has a single line and add one more:

If we continue with our previous example, adding some cloud infrastructure would now be able to set up a virtual machine that ingests directly from the source database rather than relying on someone to send an excel sheet. You can also store the raw data in a data lake allowing you to have a cheap and scalable way to store all raw data exactly in the form that it comes from. Now, we can share the data with more people and have a way to rebuild the history of our data transfer from the ground up which gives us disaster recovery.
What else can we add?
With tests, we can now make changes to the code with confidence that we won’t be releasing critical bugs that go unnoticed until crunch time. This step must be done with great care because automated tests are written using code which in itself contains the potential for it’s own nasty type of bugs. Now that we have tests, we need to make sure that there’s a repeatable, robust, and predictable runtime environment in which they can be executed. This can be done with CI/CD pipelines which are their own set of technologies.

This is what truly unlocks the holy grail of any kind of software development by making the decision to release a business one rather than a technical one.
So for each subsequent update, you are easily saving days of time. If your project is one that will live for more than a month or two, these savings in time will bring (at the very least) the following benefits:
- Faster time to market
- Smaller technical team required
- Ability to re-train and deploy models faster
- Increased customer confidence
- Happier technical workers
By now you’re hopefully getting the idea. The initial business value that is being generated is the same while you’ve unlocked vast amounts of future business value at a fraction of the cost.
At this point you might be asking yourself “is this still a 14 day project?”. No, no it’s not. And this is where things get tricky and are the difference between an uninformed AI dev team, an inexperienced AI dev team, and an excellent AI dev team.
- A uninformed AI dev team won’t know how to do it at all.
- A informed but inexperienced AI dev team will need 4X the time and build technical debt into the infrastructure, tests, and CI/CD.
- An excellent AI dev team will know the tools, best practices, and have domain experience and can deliver with only an additional 25%-50% of dev time.
Let’s assume an excellent AI dev team and make our final adjustment:
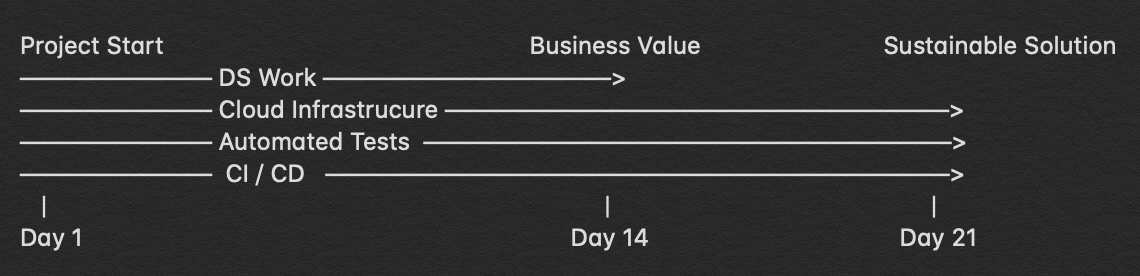
In the case of DareData, a single worker is required to have the skills to do all of this which keeps costs under control. In other organizations this may be split across multiple workers or even departments.
Wide Effort Benefits
Remember how much time it took when we were making a Narrow Effort to make even the smallest change? Remember that, in the worst case scenario of new dev, it could be up to a week? With all of this infrastructure in place to support them, we now look like this:

You can make and release changes so quickly I’m not even able to express it in my little ascii-art diagrams.
Notice that the time to original business value has not changed. The effort has indeed been extended a bit but, much more pronounced, is the significant widening of the effort. Running projects like this in traditional application dev shops isn’t as common as it should be but the best ones definitely do it. Finding teams that work in DS/ML/AI and do this is incredibly rare and this needs to change.
Notice that the time to original business value has not changed
As of this writing, many best practices have yet to be established when it comes to testing and CI/CD for AI systems in particular. At DareData, this is a key focus and one of the main reasons that we are a services company. Although we most certainly do have preferred technologies and methodologies each and every project we work on is, at some level, custom because it needs to be.
For a much more technical and in-depth description, see Martin Fowler’s excellent description of CD4ML. We at DareData proudly implement as many of the CD4ML principles as possible in every project that we do.
The Practical Path to AI
If by now you still remember the original title of this post, you might be a bit confused. What does cloud infrastructure, testing, CI/CD, etc. have to do with AI? Isn’t AI all about Machine Learning algorithms, robots acting like humans, and surprising automations? Well, yes, it is. However a trained machine learning model that sits on a smart person’s laptop doesn’t generate any value. An academic paper showing some percentage increase in accuracy for image recognition does nothing until it is deployed. All of this brainpower and investment is wasted unless you can continuously iterate, experiment, and deploy your solutions.
The current strategy that much of industry seems to be pursuing right now is to hire a bunch of clever Data Scientists and tell them to “do Machine Learning stuff”. 6 months to a year later, they are mired in technical debt. The pile of super smart scientists are spending all of their time debugging code in production, configuring servers, doing basic BI, and complaining that they are not doing Machine Learning. They eventually grow tired of not having a path to success and leave. Sorry not sorry but when working in industry, that’s the job. Even the most research-oriented ML folks working at a lab like Deep Mind spend 50% of their time researching. The other 50% is spent on some kind of engineering.
Can we help you?
If you suspect you have data which is not being used to it’s full potential, please contact me at sam@daredata.engineering. We’re happy to do a free strategic consulting session or two in order to understand if and how we might be able to work together to bring sustainable AI and ML into your organization.
