

Learn how we build data lake infrastructures and help organizations all around the world achieving their data goals.
In today's data-driven world, organizations are faced with the challenge of managing and processing large volumes of data efficiently. To overcome this challenge, many companies are turning to Data Lake solutions, which provide a centralized and scalable platform for storing, processing, and analyzing data.
Building a data lake infrastructure is a highly beneficial endeavor, not just for the immediate use of data, but also for its potential to foster the growth of analytics across the organization. We've seen this happen in dozens of our customers: data lakes serve as catalysts that empower analytical capabilities.
And what is the reason for that? If you work at a relatively large company, you've seen this cycle happening many times:
- Analytics team wants to use unstructured data on their models or analysis. For example, an industrial analytics team wants to use the logs from raw data.
- Current infrastructure does not support the storage and use of data with those characteristics (either due to size or format restrictions).
- From this point on, two things may happen: either the analytics team goes forward but will not be able to deploy their findings or they will discard the usage of the data from the project.
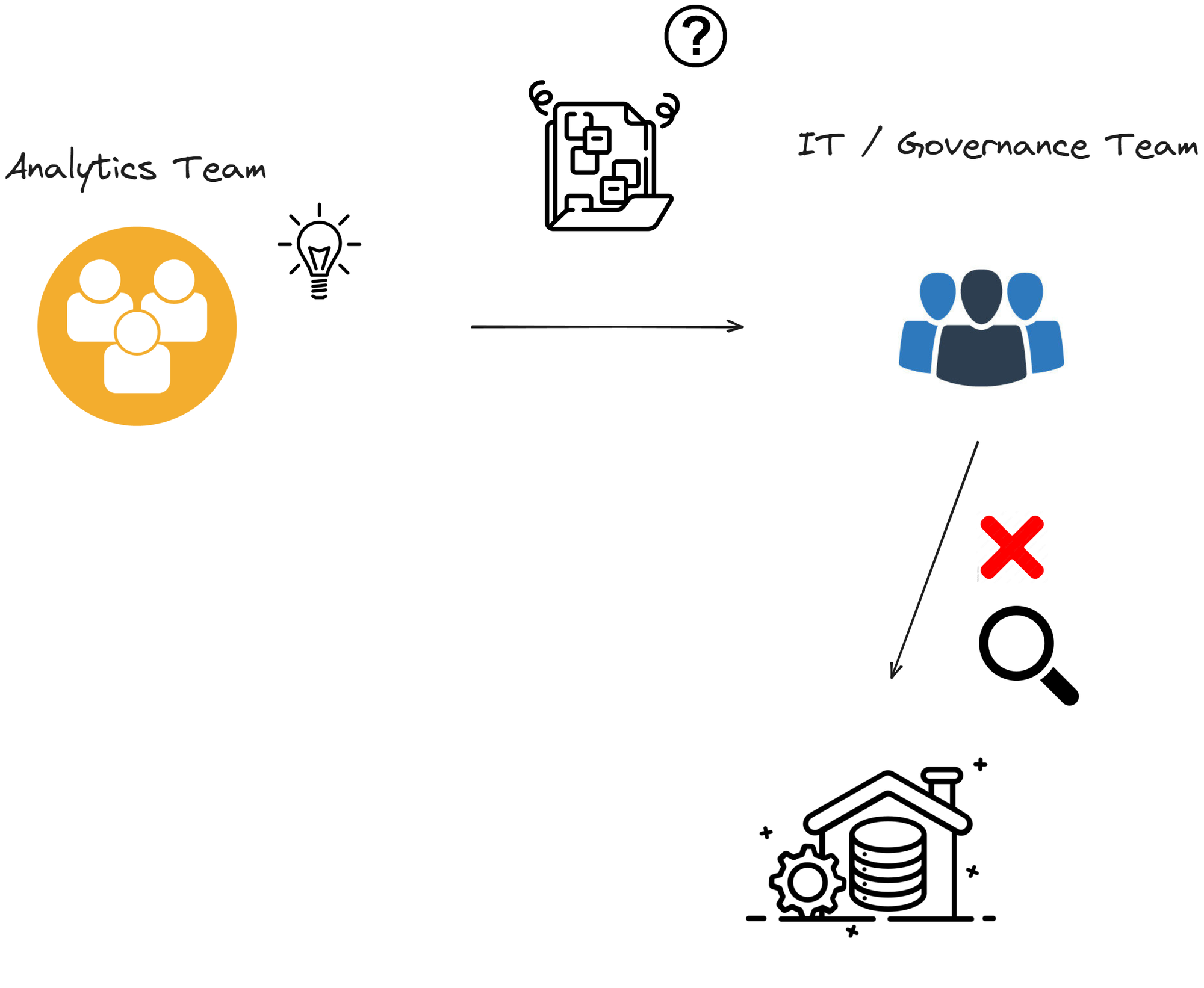
If you work for a large corporation, you are probably familiar with the following flow:
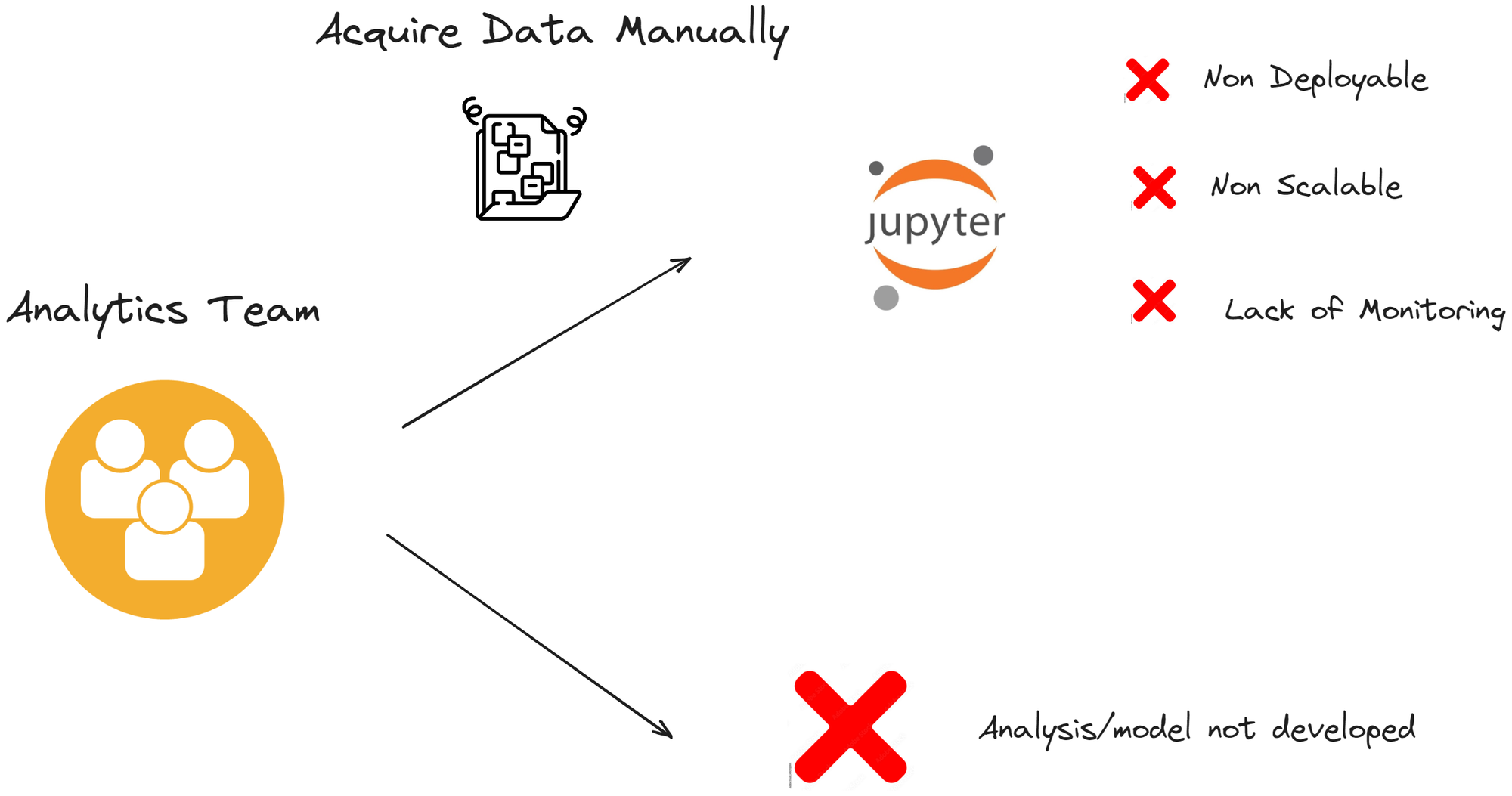
We are confident that our expertise in building data infrastructures, specifically data lakes, can be immensely valuable to those embarking on a similar journey. In this blog post, we aim to share practical insights and techniques based on our real-world experience in developing data lake infrastructures for our clients - let's start!
Understanding the Architecture
No company is alike and no infrastructure will be alike. Although there are some guidelines that you can follow when setting up a data infrastructure, each company has it's own needs, processes and organizational structure.
The initial stage when constructing a Data Lake solution involves defining the overall architecture and how the data lake will fit in. Since each company is unique, numerous variables come into play when determining the architecture that best suits your data lake:
- Data volume: What's the expected size of the data that will be ingested into the data lake?
- Users: Who are users that will interact with your data and what's their technical proficiency?
- Data Sources: How different are your data sources? And what is their format?
- Latency: What is the minimum expected latency between data collection and analytics?
This phase primarily consists of engaging in extensive discussions with stakeholders to identify areas of data insufficiency and gathering requirements. The architecture of a data lake project may contain multiple components, including the Data Lake itself, one or multiple Data Warehouses or one or multiple Data Marts.
- The Data Lake acts as the central repository for aggregating data from diverse sources in its raw format. Typically, it is advisable to retain the data in its original, unaltered format when transferring it from any source to the data lake layer.
- The Data Warehouse(s) facilitates data ingestion and enables easy access for end-users. This is the first layer where data may be structured around the typical row-column format.
- The Data Mart(s) contain the aggregated layer where data is modeled according to specific business needs. Normally, data mart is the layer where non-technical users may access the data or that feeds visualization layers.
Test, Test, Test
With the flexibility of data lake infrastructures, there's also a higher likelihood that your pipelines may fail - particularly when you are acquiring data from sources that you don't control (APIs, Scraping the Web, etc.).
Setting up our data testing framework early on will save you hundreds of hours (seriously) when you will need to debug your data pipelines in the future. Using a test-oriented development framework for pipelines that have a higher likelihood of breaking will help you catch edge cases in the future and deal with bugs that may cause serious disruptions in your ETL processes.
Learning about general unit testing frameworks such as PyTest or Airflow's testing framework will be very helpful during the development of your ETL processes!
Access to Data Lake Storage
Either via command line or a SQL interface, it may be beneficial to give your users power to access raw data stored in the lake layer. This may prevent that users from relying solely on pre-defined aggregations or data models. By allowing direct access to raw data, users can perform custom analyses, run complex queries, and derive insights that may not be captured in predefined views or summaries.
Furthermore, CLI or SQL access can foster a culture of data exploration and innovation within your organization. Users can experiment with different data transformations, combine disparate datasets, and discover new patterns or relationships. This flexibility can lead to valuable insights and opportunities for business growth.
However, it's important to strike a balance between providing access and maintaining data governance and security. Implementing proper access controls, monitoring mechanisms, and data anonymization techniques can help mitigate potential risks associated with direct access to raw data.
Ultimately, the decision to provide access to the data lake layer depends on the specific requirements, user base, and use cases of your data lake. It's beneficial to gather feedback from your users and stakeholders to ensure the chosen access method aligns with their needs and workflows.
Explore Open Source Tools
Open source tools have revolutionized the field of Extract, Transform, Load (ETL) by providing flexible, scalable, and cost-effective solutions for data integration and processing. Some of the most famous are:
- Apache Airflow: Apache Airflow is a powerful workflow orchestration tool widely used for ETL processes. It allows you to define and schedule complex workflows as Directed Acyclic Graphs (DAGs) using its rich ecosystem of operators. With AirFlow, you can easily integrate with various data sources, perform transformations, and load data into your desired destinations.
- Apache NiFi: Apache NiFi is a data integration platform that enables the automation of data flows across various systems. It provides a user-friendly graphical interface to design data pipelines with a drag-and-drop approach. NiFi supports data routing, transformation, and enrichment with a wide range of processors.
- Talend Open Studio: Talend Open Studio is a data integration tool that supports ETL, data migration, and data synchronization. It provides a visual development environment where you can design and deploy complex ETL processes.
- Prefect is an open-source workflow orchestration and dataflow automation tool that can also be used for ETL processes. It provides a Python-native and highly flexible framework for building, scheduling, and monitoring data pipelines.
Exploring these tools should give you a very cool overview of ETL tools being used in the market today. If you need help to understand how these tools work, feel free to drop us a message!
Enhacing Notifications
In the context of a data lake, enhancing DAGs (Directed Acyclic Graphs) with email notifications can be a valuable feature. By incorporating email notifications into your data lake workflows, you can keep stakeholders informed about the progress and status of data processing activities, providing transparency in the overall data infrastructure.
Here's some benefits of using email notifications to DAGs / Processes:
- Monitoring and Alerting: Email notifications can serve as a means of proactive monitoring and alerting for your data lake pipelines. You can configure notifications to be triggered upon the completion of specific tasks, failures, or critical events.
- Status Updates: Email notifications provide a convenient way to communicate status updates to relevant team members or stakeholders. .
- Exception Handling: In cases where errors or exceptions occur during data processing, email notifications can be configured to send alerts to designated individuals or teams with a description of the error.
When implementing email notifications for your data lake DAGs, consider using workflow orchestration tools like the ones we've provided above, which provide built-in features or integrations for email notification functionality. Also, make sure to strike a balance between having a huge influx of e-mails coming from your ETL processes and only alert stakeholders and users of things that may require their attention. In that way, you can ensure that email notifications are meaningful and not overwhelming.
In this expanded blog post, we have delved deeper into some key components we consider when building our Data Lake projects. By following the outlined steps and best practices, organizations can build a robust and future-proof data infrastructure that meets their evolving data needs.
By embracing the power of open source ETL tools and cloud environments, businesses can navigate the complexities of managing big data and pave the way for data-driven success. Remember that having a performant, transparent and efficient data transformation infrastructure is key to enhance analytics capabilities at organization of all sizes. Furthermore, fostering a culture of exploration and experimentation encourages users to delve deeper into the data and discover new insights. By providing them with the tools and capabilities to explore data from different angles, you empower them to uncover hidden patterns, trends, and opportunities that can drive innovation and growth within your organization.
Want to speak about how to setup a Data Lake for your organization? Feel free to send me an email to ivo@daredata.engineering. I would love to speak with you about these topics!
Know more about us on our website: https://www.daredata.engineering/
